![]()
- 基本概念
- 向量:一维数组
输入
- 输入:“我想买苹果手机”
- 模型收到输入后,先切词(token):[ “我”, “想”, “买”, “苹果”, “手机” ]
- 向量化 (Embedding):每个词(token)变成一个初始向量,称为 X 向量。比如“苹果”变成了 [0.1, -0.3, 0.5…],表示为 X苹果。后续计算的核心,就是迭代 X 向量。
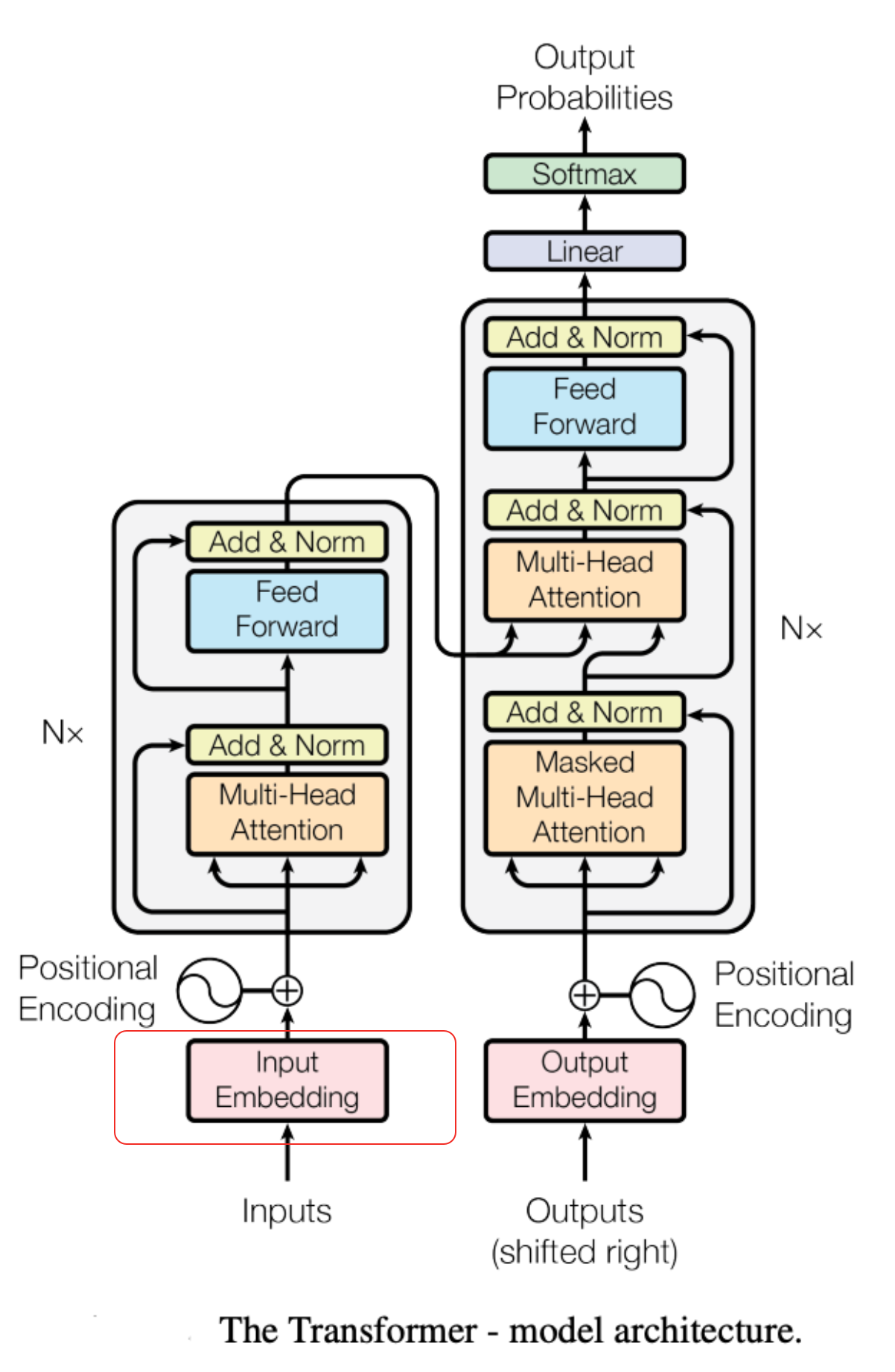
- 位置编码:模型同时对所有 token 进行了向量化,token 在句子中的“位置”需要在这一步完成。比如,“苹果”是第4个词。
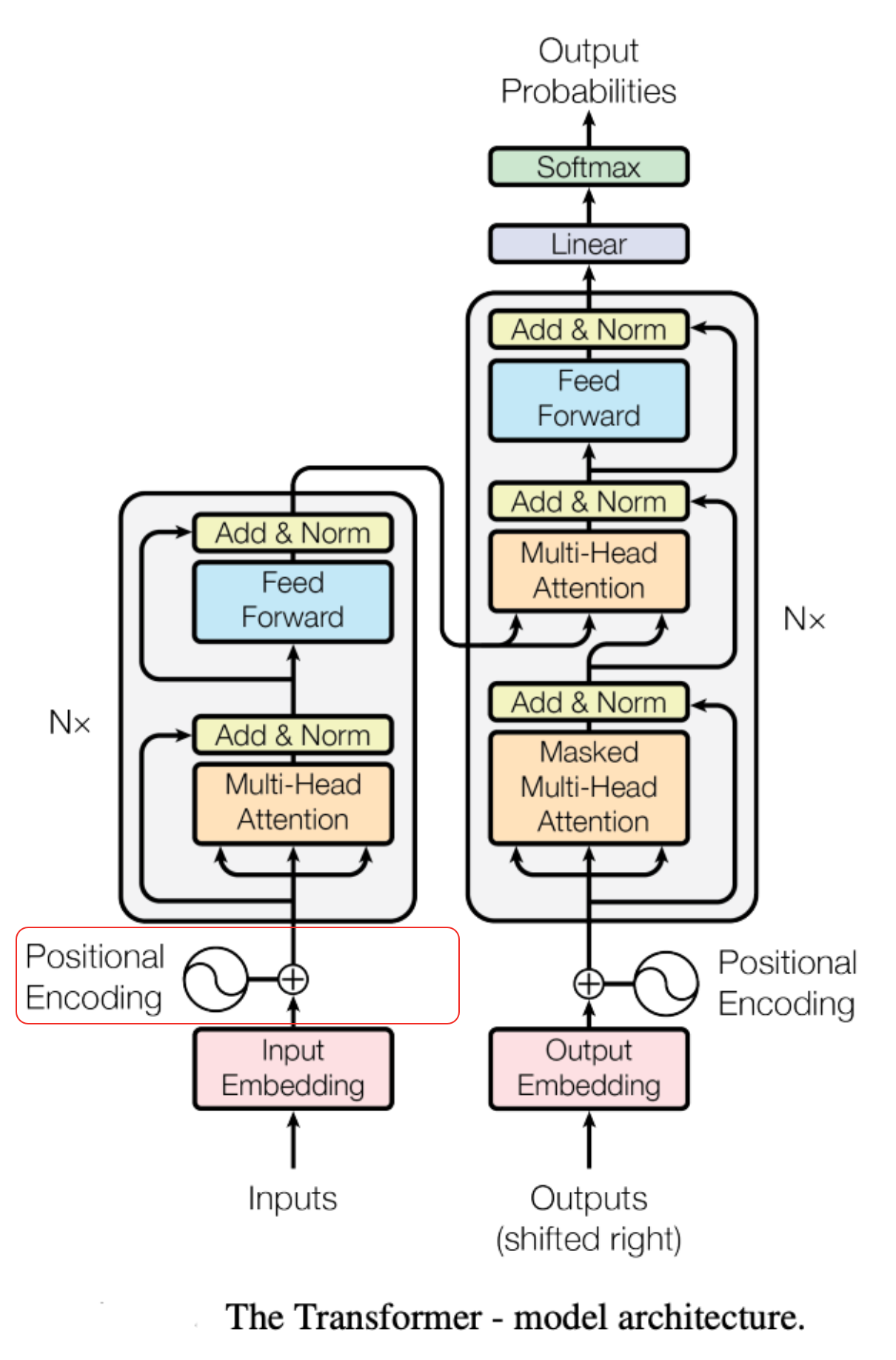
循环 - 迭代 X 向量
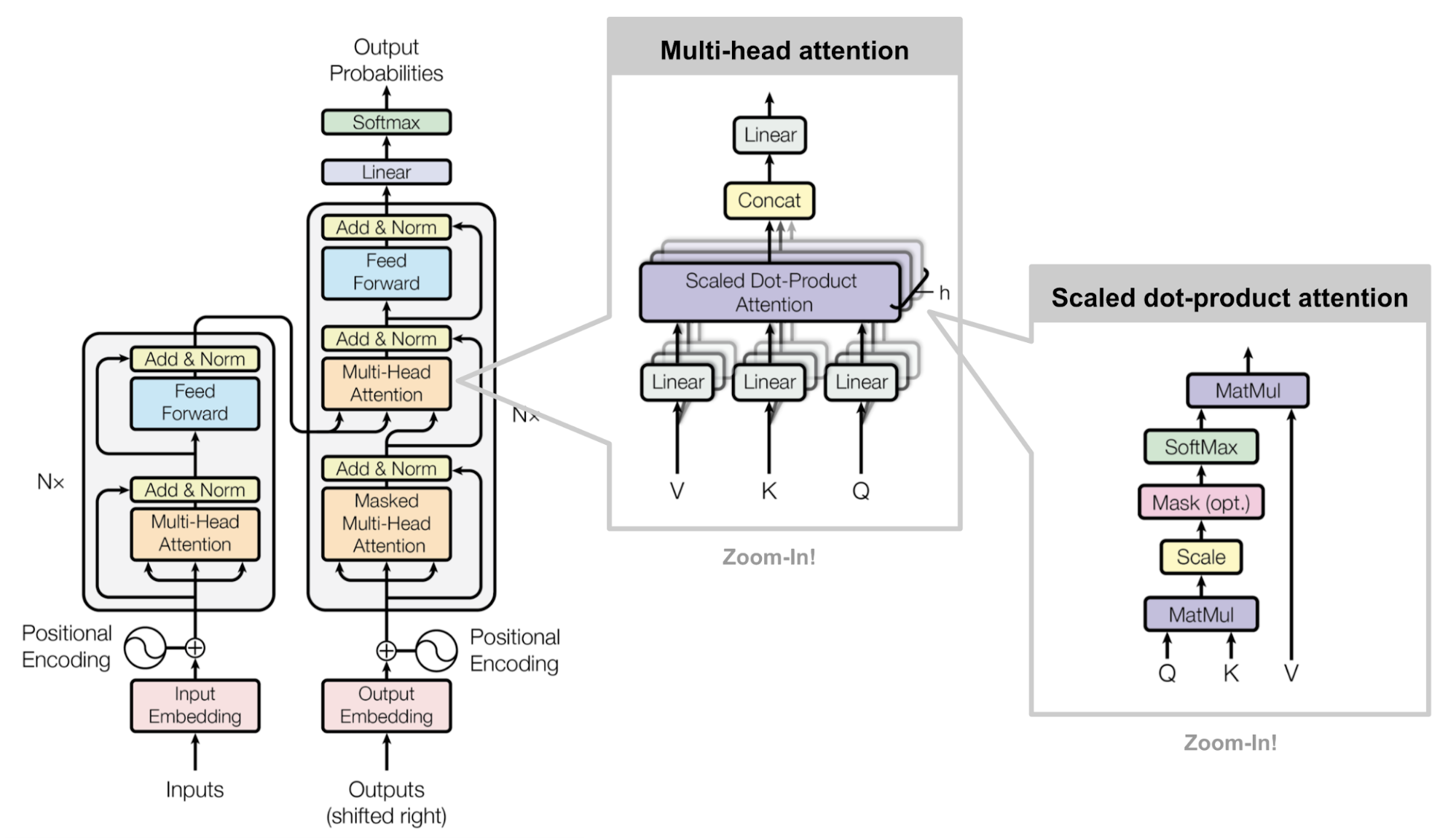
- X 向量乘以权重矩阵,拆解成 Q、K、V 三个向量。
- Q 向量:Query/查询,用来去问别人:“谁能帮我确定我的具体含义?”
- K 向量:Key/键,用来告诉别人:“我包含水果和品牌的特征。”
- V 向量:Value/值,它本身最原始的内容:“美味、昂贵”
(权重矩阵是模型经过训练后,沉淀下来的转换规则。有三种权重矩阵:生成查询的矩阵、生成键的矩阵、生成值的矩阵。)
- Q、K、V 是 X 的三个“临时工作分身”,专门为了和其他词进行交流(计算注意力)而生成的。注意力计算后,生成一个新的 X新 向量。
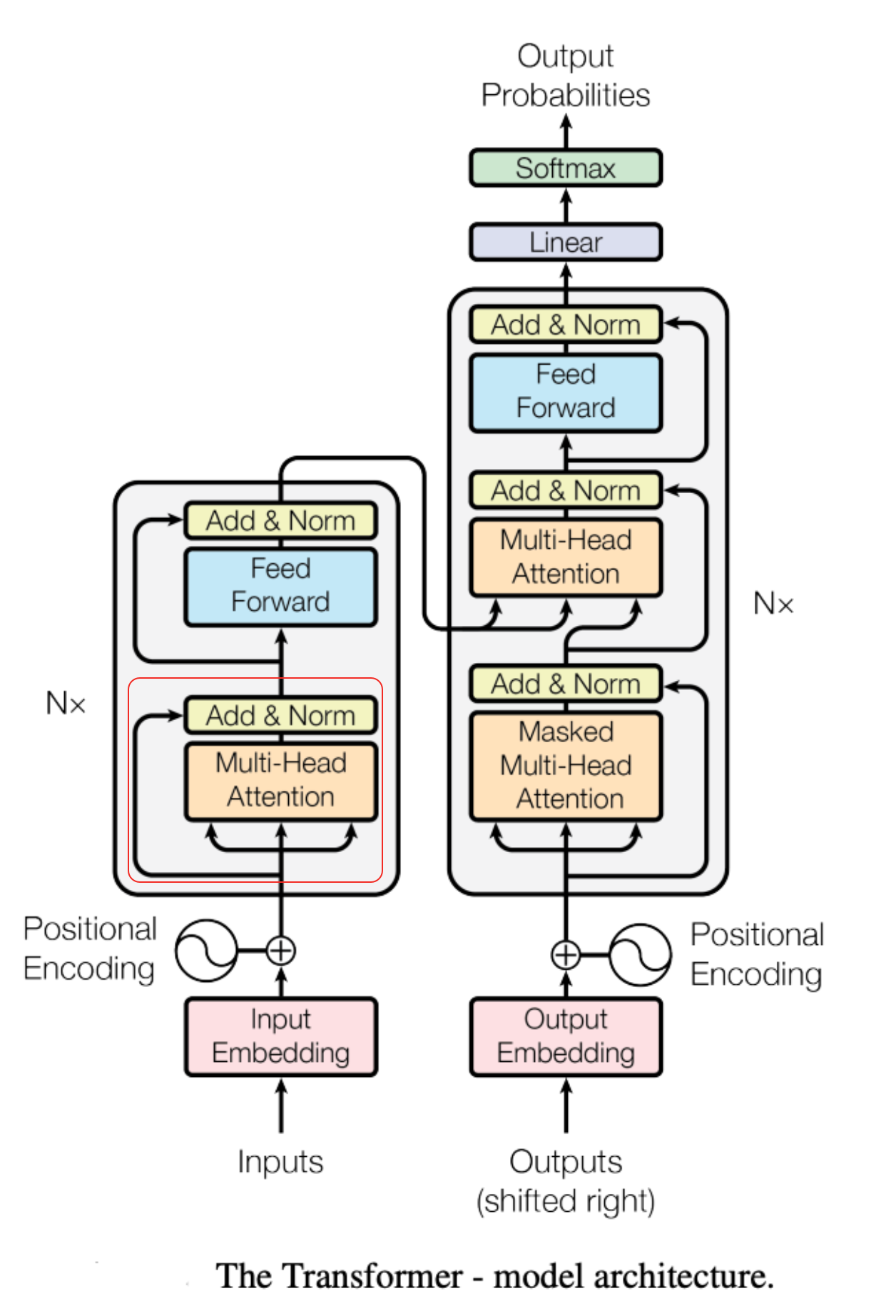
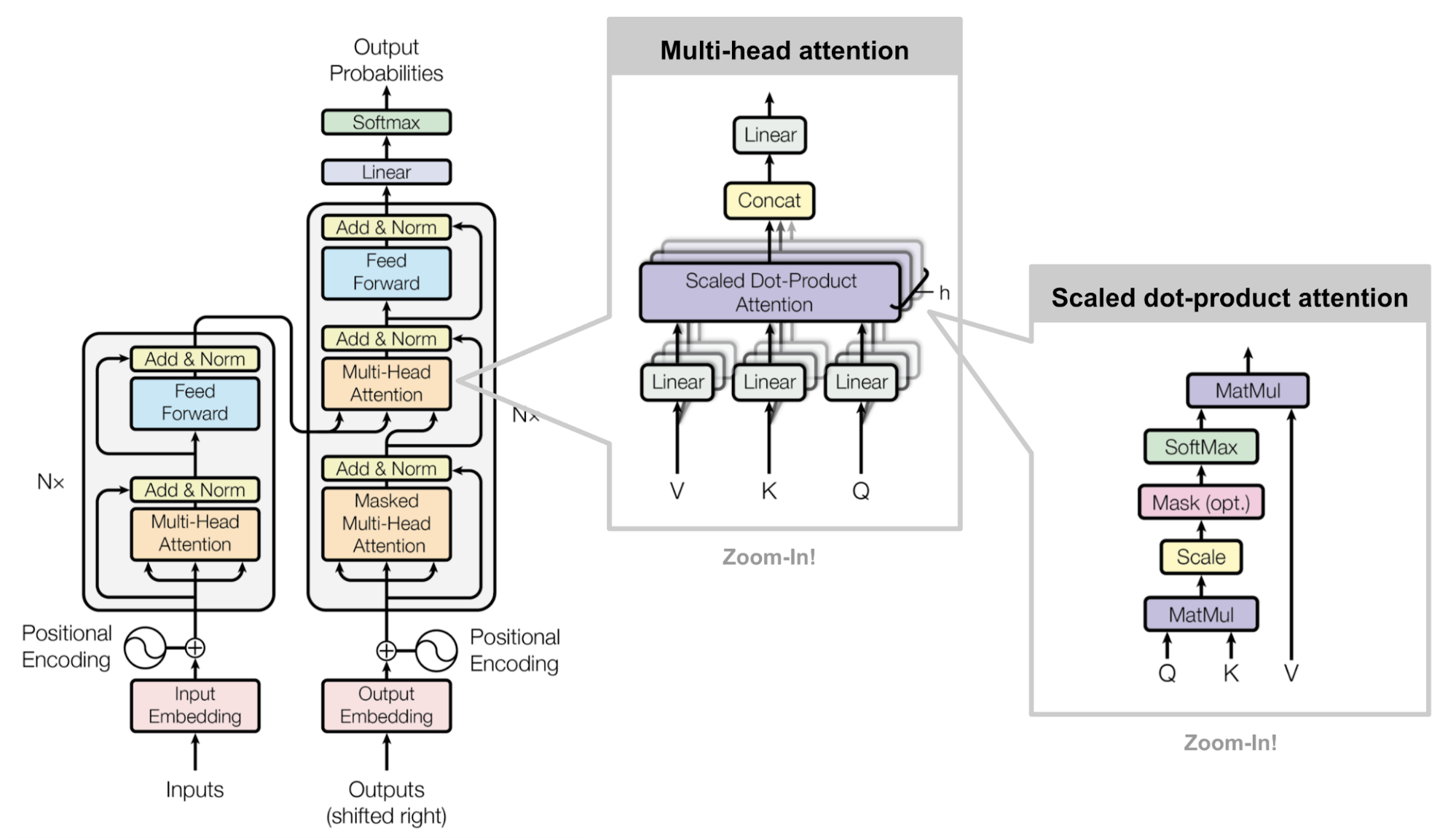
- 多头(Multi-Head)的含义:
模型不会只生成一组 Q、K、V ,而是会生成很多组。这就好比模型长了“多个脑袋”。
头 A 专门负责找语法关系(比如主谓宾)。
头 B 专门负责找情感关系(正向还是负向)。
头 C 专门负责找指代关系(“它”指的是谁)。
所有脑袋同时计算,最后把结果拼起来,为了让模型思考得更全面。
- 这个过程会进行多轮(比如,GPT-3 有 96 轮)。每一轮 X 向量都在进化,包含了越来越丰富的信息。比如:
第 1 轮思考:刚才那个更新后的 X新,变成了第二轮的输入 X 。此时它可能只是弄懂了“苹果”和“手机”连在一起。
第 10 轮思考:随着范围扩大,它搞懂了句子的语法结构(谁是主语,谁是宾语)。
第 50 轮思考:它开始理解更抽象的情感和意图(比如用户想花钱买昂贵的数码产品)。
最后一轮思考结束:那个历经千锤百炼的终极 X 向量出炉!这个向量已经包含了无比丰富的逻辑、语境和情感信息。
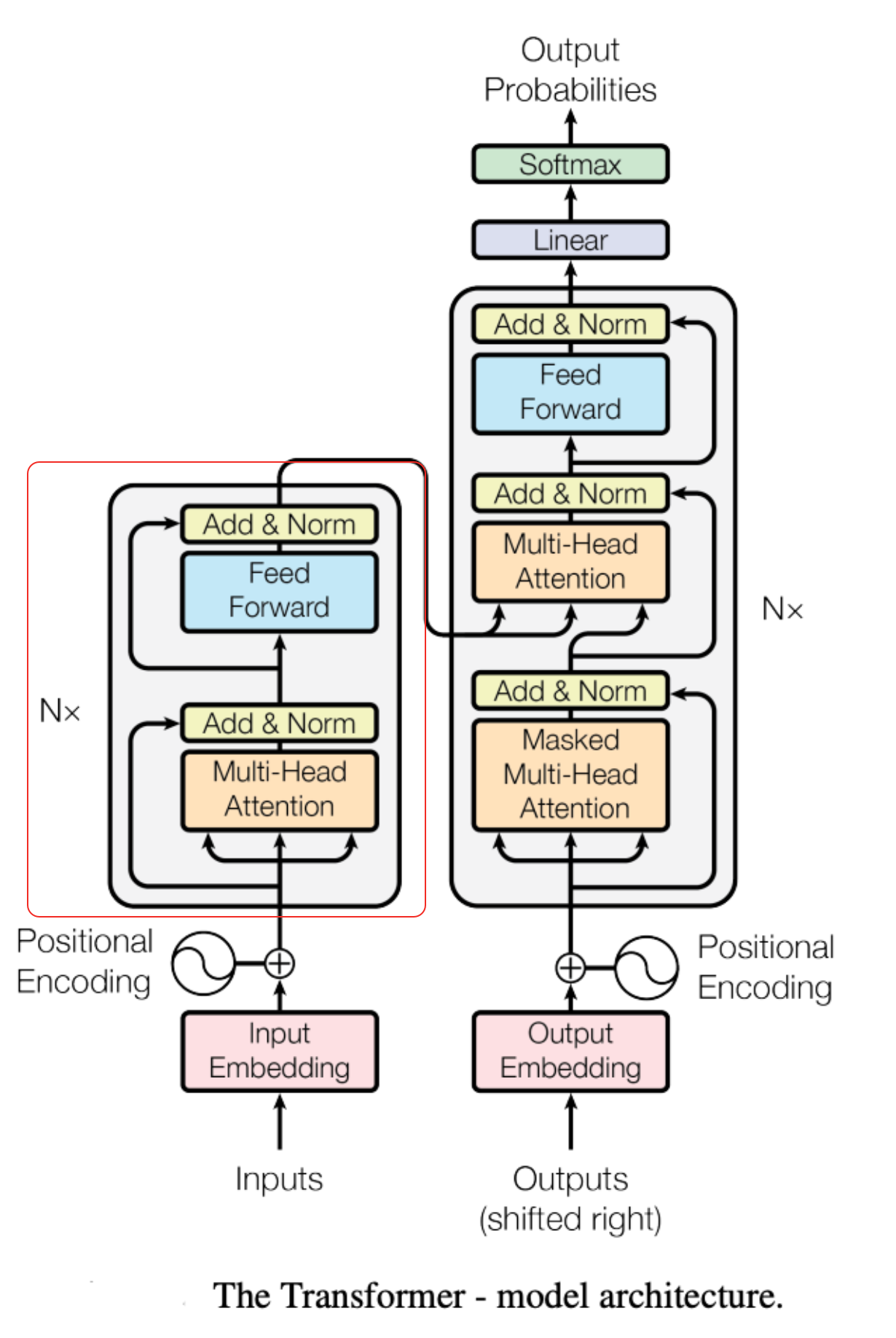
输出
- 计算下一个 token 输出什么,模型只看上一个 token 的 X 向量。比如对于上面的例子,模型只看“手机” 这个 token。
因为“手机”的终极 X 向量,其实已经相当于“整句话的总结报告”了。
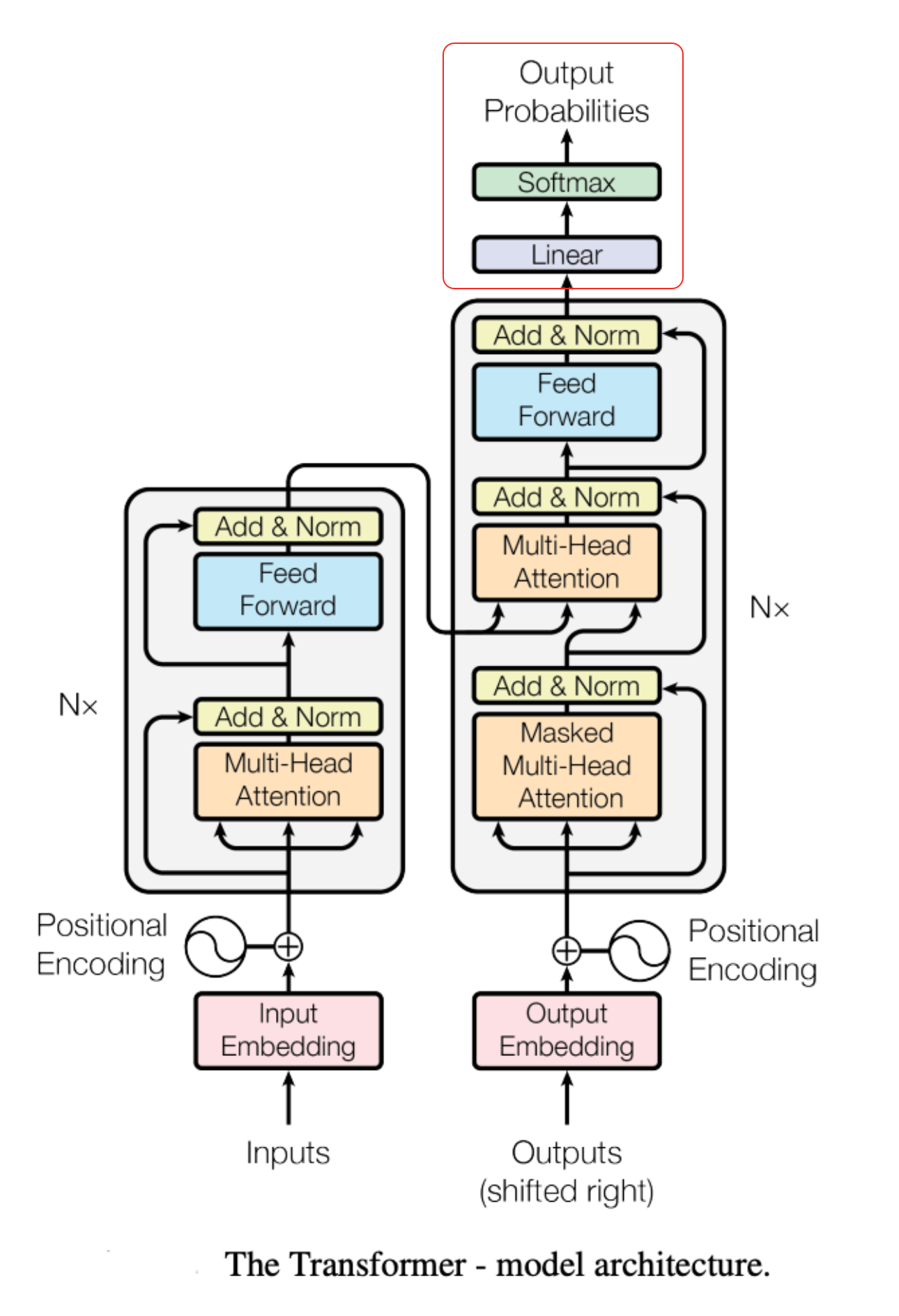
计算再下一个 token 的输出。会将前次输出的 token 拼接到句子里,重头开始、重新进行思考。
- 第一轮
输入:[ “我”, “想”, “买”, “苹果”, “手机” ];输出:”它”
- 第二轮
输入:[ “我”, “想”, “买”, “苹果”, “手机” , “它”];输出:”很”
- 第三轮
输入:[ “我”, “想”, “买”, “苹果”, “手机” , “它”, “很”];输出:”贵”
- 第四轮
输入:[ “我”, “想”, “买”, “苹果”, “手机” , “它”, “很”, “贵”];输出:<EOS> (End of Sentence,句子结束符)。
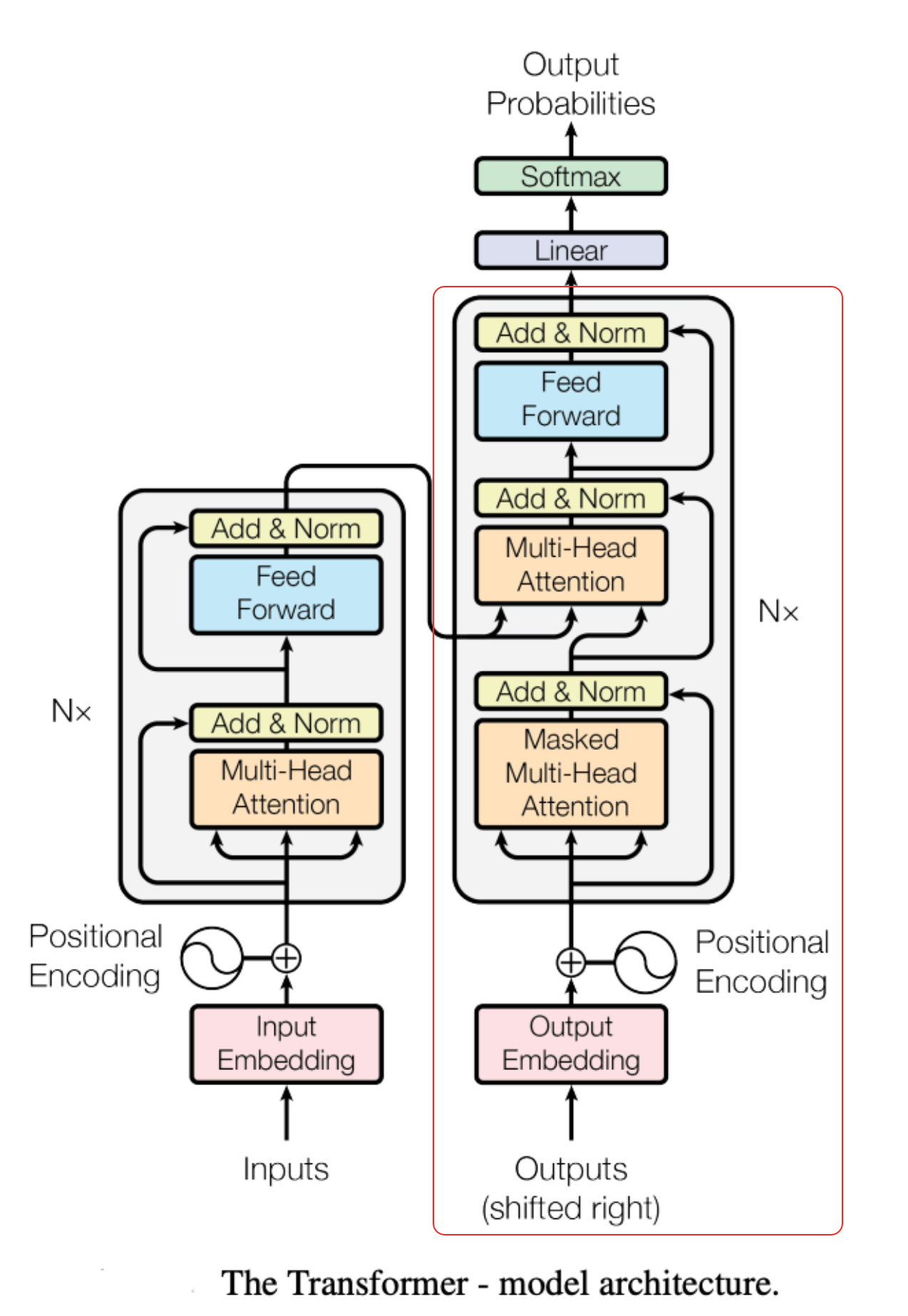
Masked Multi-Head Attention 的含义和作用
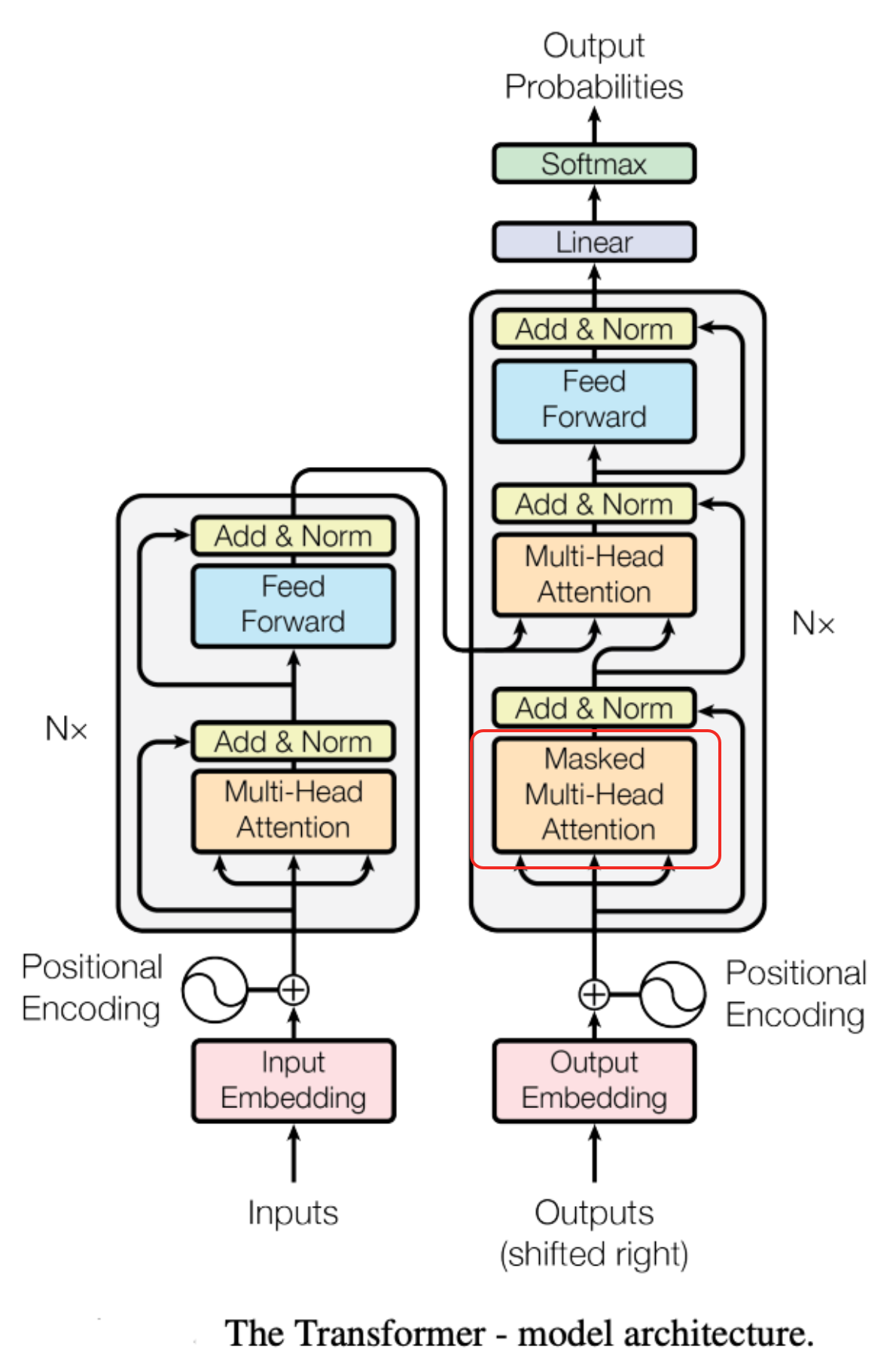
- 训练阶段:模型训练的语料是完整的,比如“我想买苹果手机”“它很贵”模型训练时都直接就能看到全貌。为了训练模型的推理能力,在训练阶段会“盖住”还没有生成的内容。
它██
它很█
它很贵
- 推理阶段:虽然在推理阶段模型本来就看不到未生成的 token,但是需要保持与训练阶段数学运算规则的一致。
ChatGPT 架构与 Transformer 论文架构的区别
- Transformer 论文中的架构,输入和输出是分开的。
- 输入阶段:token 不仅可以计算与前面 token 的注意力,也可以计算与后面 token 的注意力。
- 输出阶段:增加了 Masked 机制,token 只计算自己前面 token 的注意力。
- ChatGPT 架构采用了统一的架构。即使在输入阶段也有 Masked 机制,token 只计算自己前面 token 的注意力。
我██████
我想█████
我想买████
我想买苹███
我想买苹果██
我想买苹果手█
我想买苹果手机
KV Caching 优化
- 上面可以看到,计算 token 输出的方式非常暴力。通过 KV Caching 优化,可以节省大量计算。(空间换时间。)KV Caching 只在输出环节起作用。
- Scaled dot-product attention 计算公式
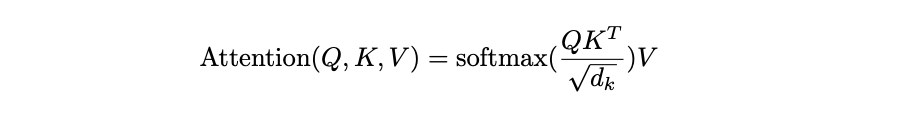
[ “我”, “想”, “买”, “苹果”, “手机” ],计算过程示例
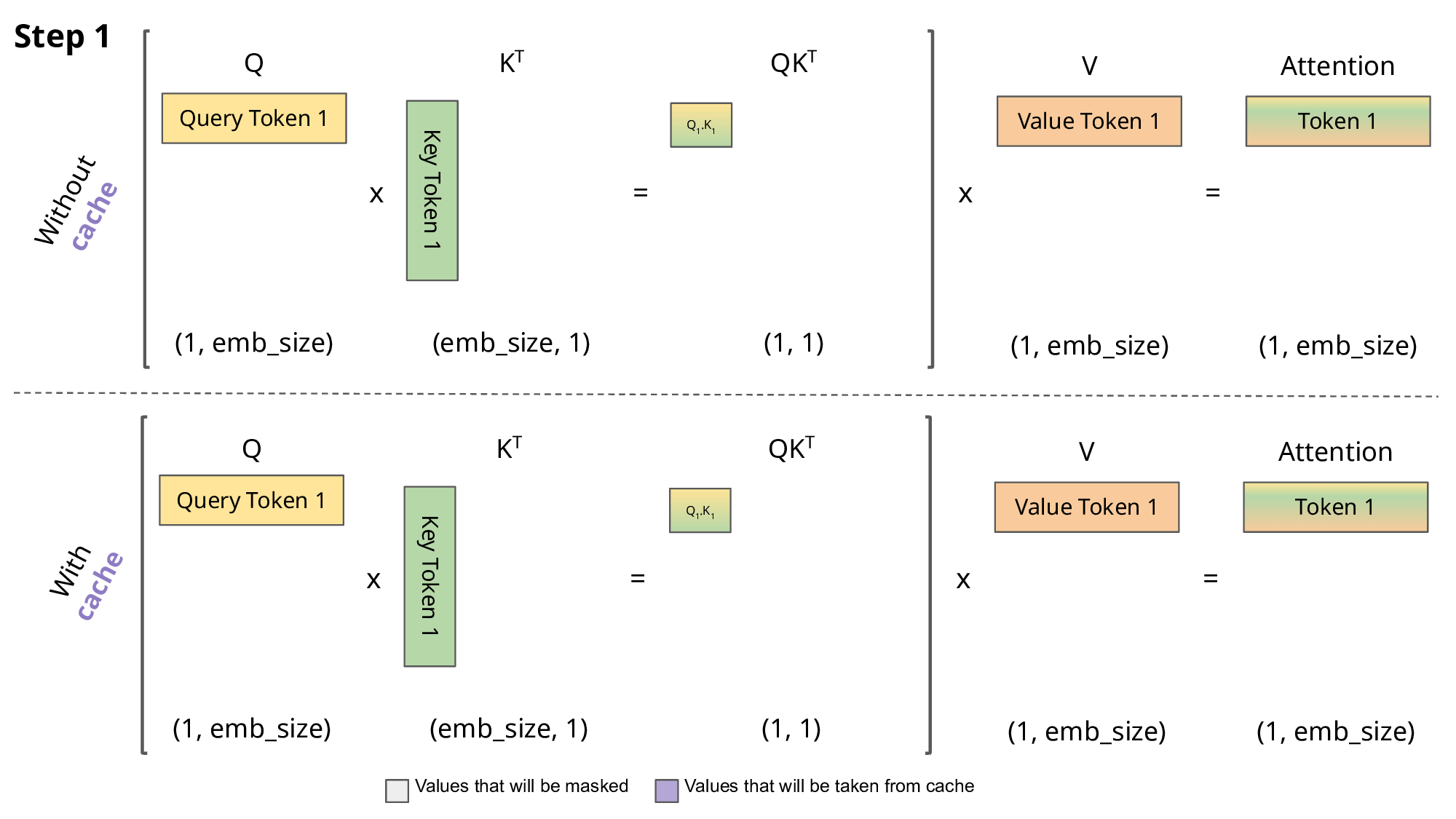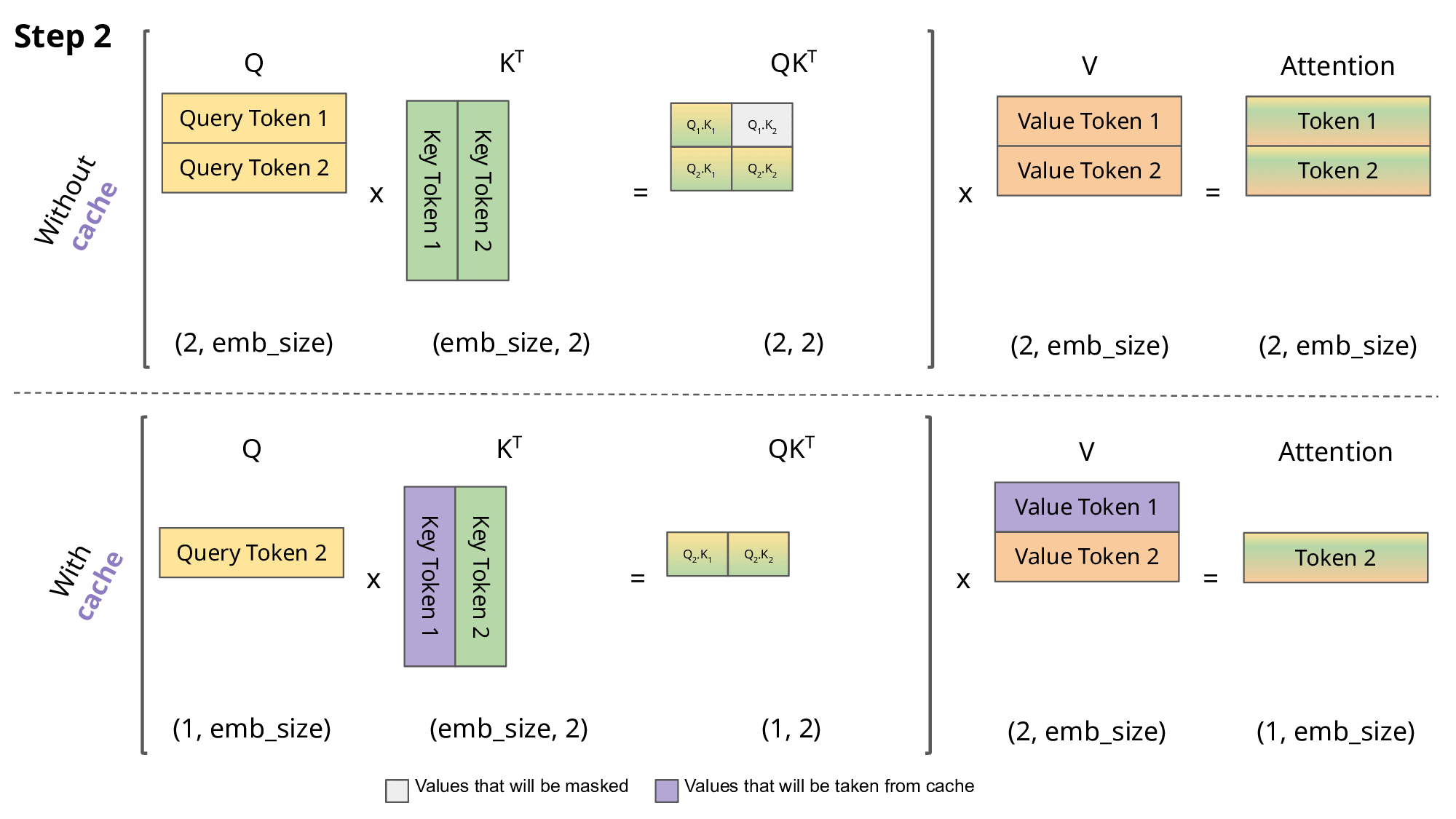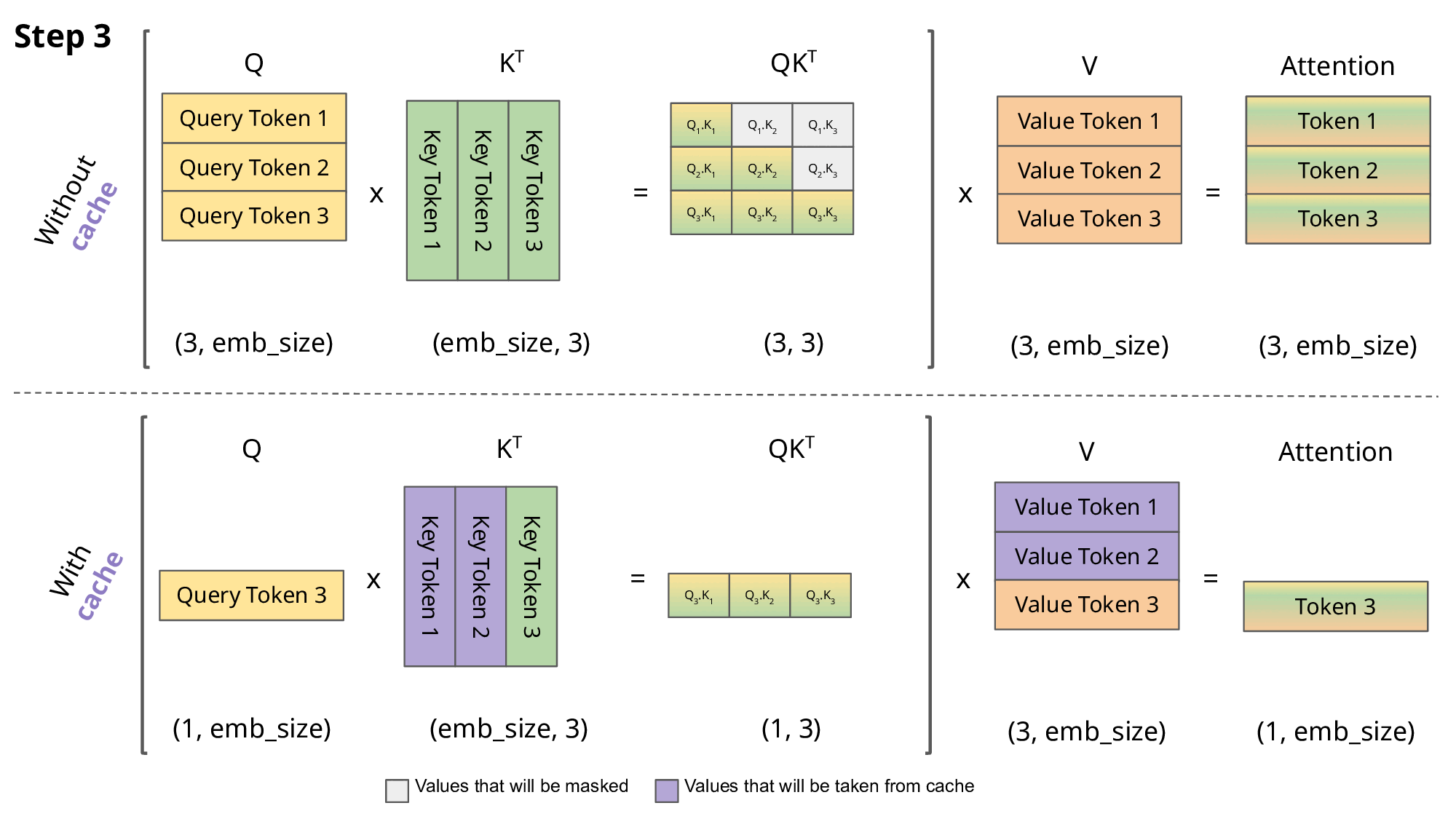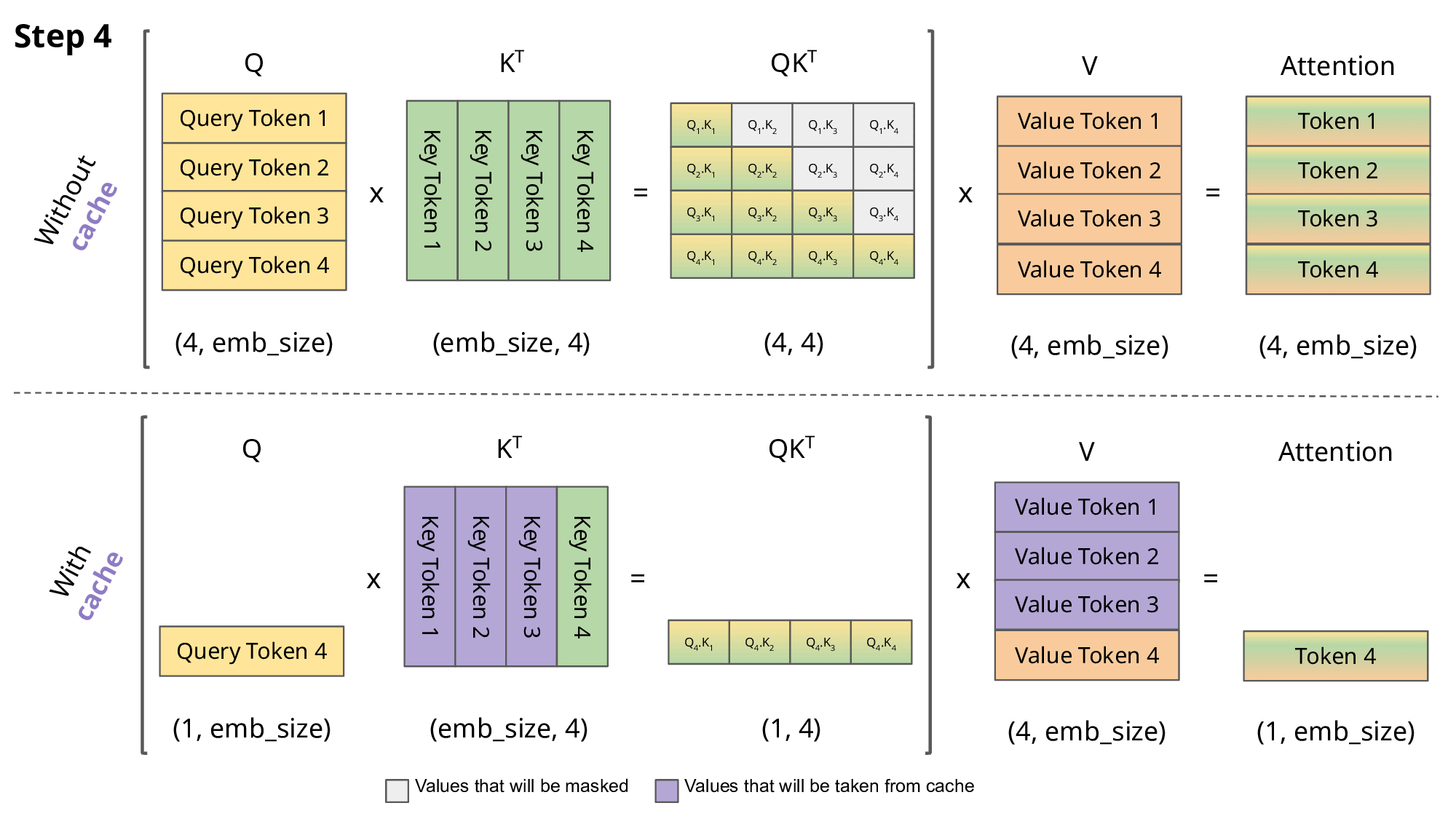
- 第 0 步:准备工作。进入模型后,每个 token 都带有初始向量 X ,分别乘以了权重矩阵后获得 Q、K、V
我: Q1、 K1、 V1
想: Q2、 K2、 V2
买: Q3、 K3、 V3
苹果: Q4、 K4、 V4
手机: Q5、 K5、 V5
- 第 1 步:处理“我”(时间点 1)由于 Mask 机制的存在,它们只能往左看!
Q1 只能匹配到 K1
得出权重 (Softmax):100% 的注意力只能放在自己身上。
吸收内容 (V1新):把 100% 的 V1 拿过来。
- 第 2 步:处理“想”(时间点 2)
Q2 匹配到 K1、 K2
得出权重 (Softmax):假设 30% 给“我”,70% 给自己。
吸收内容 (V):把 30% 的 V1和 70% 的 V2混合在一起。
本轮结果:此时更新后的“想”向量,不再是单纯的“思考/希望”,它变成了一个复合概念:“某人(我)产生了一个念头”。
KV Caching 机制: K1、 V1使用第 1 步计算后缓存的值
- 第 3 步:处理“买”(时间点 3)
Q3匹配到 K1、 K2、 K3
得出权重:假设 10%给“我”,40%给“想”,50%给自己。
吸收内容 (V):把 10% 的 V1、40% 的 V2、50% 的 V3 混合在一起。
本轮结果:此时的“买”向量,已经吸纳了前置语境,它的含义变成了:“一个强烈的购物意愿(我想买)”。
KV Caching 机制: K1、 V1、 K2、 V2使用前 2 步计算后缓存的值
- 第 4 步:处理“苹果”(时间点 4)—— 💡关键转折点!
Q4匹配到 K1、 K2、 K3、 K4
得出权重 (Softmax):它把大部分注意力放在了“买”和自己身上。
吸收内容 (V):混合 V1、 V2、 V3、 V4
本轮结果:在没有看到“手机”的情况下,此时更新后的“苹果”向量,处于一种“薛定谔的状态”。它代表着“某人打算购买的一个叫苹果的物品(可能是水果,也可能是设备)”。
KV Caching 机制: K1、 V1、 K2、 V2、 K3、 V3使用前 3 步计算后缓存的值
- 第 5 步:处理“手机”(时间点 5)—— 🌟终极大融合!
Q5匹配到 K1、 K2、 K3、K4、 K5
得出权重:假设 5%给[我/想],15%给[买],45%给[苹果],35%给自己。
吸收内容 (V):按照上面的百分比,把前面所有词的 V 狠狠地“吸”到自己身上!混合成一杯极其丰富、完美的鸡尾酒。
本轮结果:“手机”这个词的终极向量,已经变成了一个“黑洞”。它不仅包含了“手机”本身的含义,它还完美地吸收了“苹果品牌”的定语,以及“我想买”的用户意图。
KV Caching 机制: K1、 V1、 K2、 V2、 K3、 V3、 K4、 V4使用前 4 步计算后缓存的值
对应的运算过程如下图